首页 >> 综合 > 精选知识 >
创新的域自适应方法可从单深度图像进行3D人脸重建
从视觉效果重建3D 脸部对于数字脸部建模和操作至关重要。传统方法主要依赖于 RGB 图像,这些图像容易受到光照变化的影响并且仅提供 2D 信息。相比之下,深度图像可以抵抗光照变化,直接捕获 3D 数据,为稳健的重建提供了潜在的解决方案。最近的研究转向深度学习,以从深度数据中进行更稳健的重建;然而,缺乏具有准确 3D 面部标签的真实深度图像阻碍了训练过程。由于领域差异,使用自动合成数据进行训练的尝试在推广到现实场景时遇到了限制。
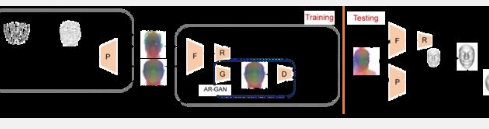
为了应对这些挑战,蔡晓旭领导的研究团队于 2024 年 2 月 15 日在 高等教育出版社和施普林格·自然联合出版的《计算机科学前沿》上公布了他们的最新发现。他们的研究引入了一种新颖的领域自适应重建方法,利用深度学习以及自动标记的合成数据和未标记的真实数据的融合。这种方法有助于根据现实世界中捕获的单个深度图像重建 3D 面部。他们的方法实现了域自适应神经网络,分别致力于预测头部姿势和面部形状。每个网络都使用针对其组件定制的特定策略进行训练。头部姿势网络使用简单的微调方法进行训练,而更强大的对抗域适应方法则用于训练面部形状网络。预处理的初始步骤涉及将深度图像中的像素值转换为相机空间内的 3D 点坐标。此过程允许在重建网络中利用 2D 卷积来处理 3D 几何信息。网络输出采用 3D 顶点偏移,建立更集中的目标分布以促进学习过程。
该方法在具有挑战性的现实世界数据集上进行了彻底评估,证明了其与最先进技术相比的竞争性能。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
分享:
最新文章
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
QQ多米试驾线下预约活动为了让更多用户感受QQ多米的独特魅力,我们特别推出了线下试驾预约活动。这不仅是一次...浏览全文>>
-
阜阳长安启源A07以其卓越的性能和豪华配置吸引了众多消费者的目光。作为一款定位高端市场的新能源车型,长安启...浏览全文>>
-
【安徽淮南大众CC新车报价2025款大公开】大众CC作为一款兼具运动感与豪华质感的轿跑车型,一直深受消费者喜爱...浏览全文>>
-
2025款长安猎手K50在安徽淮南地区的最新价格已新鲜出炉,为准备购车的朋友带来全面解析。这款车型以其高性价比...浏览全文>>
-
在安徽滁州购买长安猎手K50时,了解其落地价和省钱技巧至关重要。长安猎手K50是一款实用性强的皮卡车型,适合...浏览全文>>
-
途锐新能源是大众旗下的一款高端插电混动SUV,目前在安徽阜阳地区有售。其官方指导价约为58万元起,但实际成交...浏览全文>>
-
2025款大众CC作为一款兼具运动与豪华的中型轿车,备受关注。目前市场指导价大约在25万至35万元之间,具体价格...浏览全文>>
-
2024款探岳X作为一款备受关注的中型SUV,在市场上以其时尚的设计和出色的性能吸引了众多消费者。根据最新市场...浏览全文>>
大家爱看
频道推荐
站长推荐
- QQ多米试驾线下预约
- 安徽滁州长安猎手K50落地价,买车省钱秘籍
- 淮南大众CC新款价格2025款多少钱?买车攻略一网打尽
- 瑞虎8 PRO试驾,畅享豪华驾乘,体验卓越性能
- 安徽阜阳长安启源A05多少钱 2025款落地价,换代前的购车良机,不容错过
- 保时捷Macan试驾的流程是什么
- 安徽淮南大众ID.3多少钱?购车攻略在此
- 阜阳揽巡落地价,豪华配置超值价来袭
- 安徽池州威然 2024新款价格与配置的完美平衡
- 奇瑞瑞虎9试驾,新手必知的详细步骤
- QQ多米价格,换代前的购车良机,不容错过
- 池州迈腾GTE新款价格2022款多少钱?选车秘籍与优惠全公开
- 岚图追光多少钱 2024款落地价走势,近一个月最低售价25.28万起,性价比凸显
- 天津滨海威然 2024新款价格,最低售价28.98万起,入手正当时
- 蚌埠途昂新款价格2025款多少钱?购车必看
- 坦克400预约试驾全攻略
- 天津滨海ID.7 VIZZION价格,各配置车型售价全揭晓,性价比之王
- 安庆帕萨特最新价格2025款,最低售价12.35万起,入手正当时
- 亳州宝来新款价格2025款多少钱?选车指南与落地价全解析
- 生活家PHEV 2025新款价格,最低售价63.98万起现在该入手吗?